Ao construir um stack de Inteligência Artificial (IA), devem ter prioridade às tarefas que executam a ingestão de dados, o processamento paralelo, o processamento de stream, a computação distribuída (workloads, ou cargas de trabalho) e o armazenamento. Em Machine Learning (ML), o processamento paralelo é diferente do processamento de stream. O Kafka e o Spark Streaming (uma extensão do Spark) são processadores de stream que ingerem dados de logs de servidores, dispositivos IoT, sensores e outros. Depois são transformados em um formato mais útil que pode ser enviado para outros sistemas.
Frameworks de IA, como o TensorFlow e o Pytorch, estão prontos para executar processamento paralelo, dividindo tarefas em partes e distribuindo as cargas de trabalho em várias GPUs e nós.
Usando o TensorFlow com Spark
Fundada em 2013, a Databricks é a empresa por trás do Apache Spark. Tim Hunter, Ph.D. e engenheiro de software da Databricks, escreveu um artigo no qual descreve os benefícios de usar o Spark com o TensorFlow. O Apache Spark (não o Spark Streaming) pode ser usado para dimensionar cargas de trabalho do TensorFlow durante o treinamento de modelos de ML e a posterior fase de inferência.
Para o treinamento de modelos, o Spark é útil para dimensionar o ajuste de hiperparâmetros. O ajuste de hiperparâmetros se enquadra no termo geral de “Otimização de modelo”. O Google descreve o mesmo processo como “Otimização de hiperparâmetros”. Assim, o processo de ajuste dos parâmetros certos em cada modelo é de vital importância, na medida em que impacta o desempenho e a precisão de um modelo.
Jesus Rodriguez, CTO da IntoTheBlock, escreve que “ramais completos de machine learning e as teorias de aprendizagem profunda (deep learning) foram dedicados à otimização de modelos” e “a otimização muitas vezes envolve elementos de ajuste que ficam fora do modelo, mas que podem influenciar fortemente seu comportamento”. Assim, os hiperparâmetros são os elementos ocultos em modelos de aprendizagem profunda que podem ser ajustados para controlar o comportamento. O TensorFlow e outros modelos incluem hiperparâmetros básicos, como taxa de aprendizado. No entanto, o processo de encontrar os melhores hiperparâmetros para um determinado modelo envolve experimentação e esforço manual.
Exemplos de hiperparâmetros
- IntoTheBlock: 1) Taxa de aprendizagem; 2) Número de unidades ocultas; 3) Largura do Kernel de Convolução.
- Google: 1) Taxa de aprendizagem; 2) Taxa de abandono na camada de abandono; 3) Número de unidades na primeira camada densa; 4) Otimizador.
- Hvass Labs: 1) Taxa de aprendizagem; 2) Número de camadas densas; 3) Número de nós densos; 4) Função de ativação.
Em um exemplo, o Hvaas Labs descreve as etapas de otimização de hiperparâmetros para um modelo específico usando o “Processo Gaussiano” e o TensorFlow.
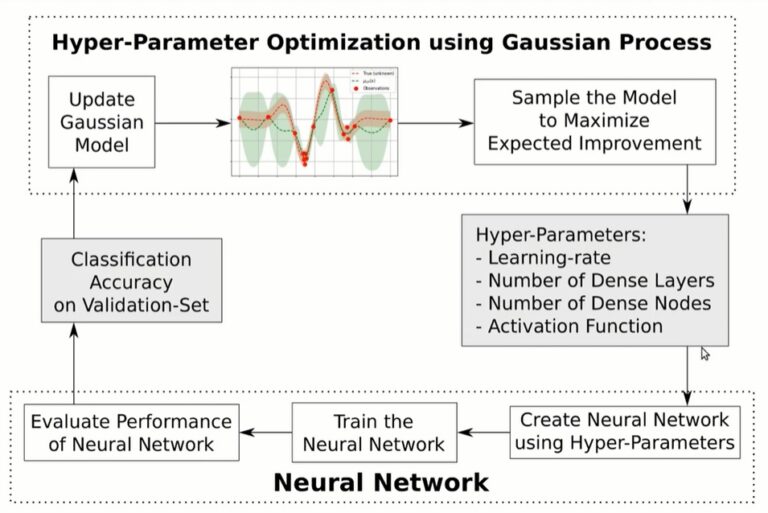
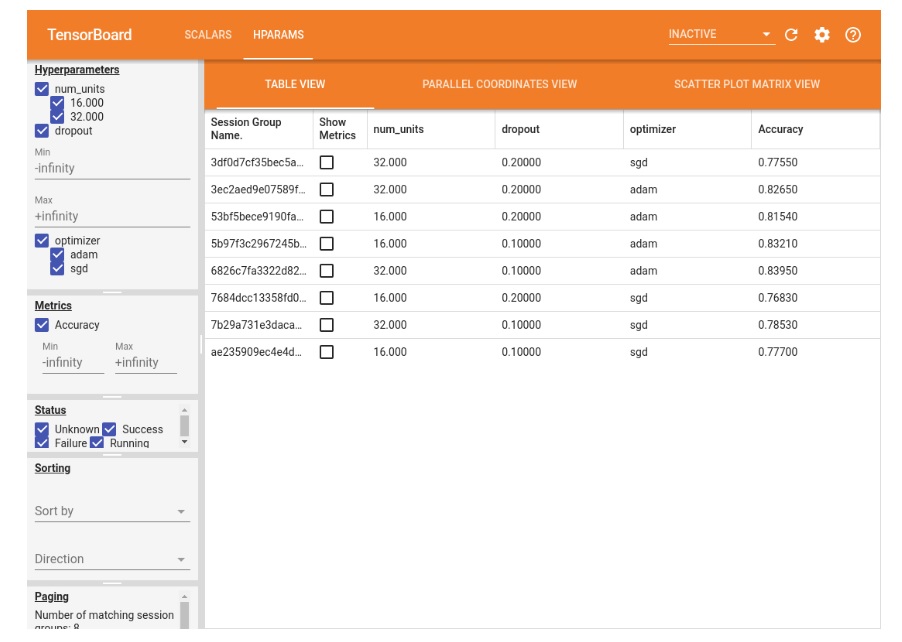
Em outro exemplo, o Google exibe três hiperparâmetros no TensorBoard para um modelo específico que inclui 1) número de unidades, 2) abandono e 3) otimizador.
Nesse artigo de Databricks, o autor descreve o processo de transformação de uma imagem, como o conjunto de dados “clássico” do NIST, em dígitos para que um modelo de Machine Learning possa lê-lo. Usando o TensorFlow, a ferramenta é capaz de ler a imagem e, em seguida, executar o cálculo matemático para transformar os pixels da imagem em “sinais” que são lidos pelo algoritmo. Embora o TensorFlow crie algoritmos de treinamento, a parte mais difícil é selecionar os hiperparâmetros certos. Se os parâmetros adequados forem selecionados, o modelo terá um bom desempenho. Caso contrário, o desempenho do modelo cai.
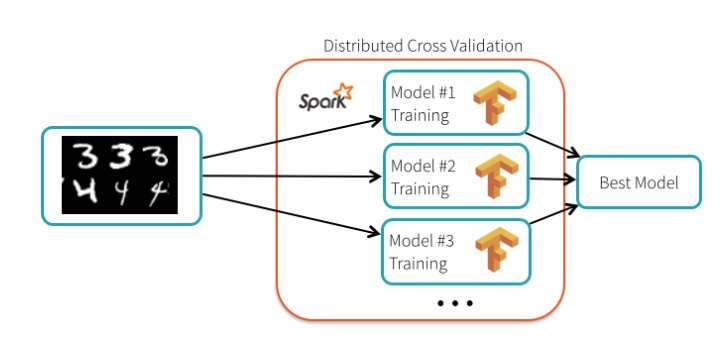
Curiosamente, o autor explica que “TensorFlow em si não é distribuído. O processo de ajuste dos hiperparâmetros é embaraçosamente paralelo e pode ser distribuído usando o Spark”. No entanto, Gonzalo Meza, um engenheiro do Google, afirma que o TensorFlow “realmente não se importa com a infraestrutura subjacente” porque há um recurso chamado tf.distribute.strategy que permite que a “API TensorFlow distribua treinamento em várias GPUs, várias máquinas ou TPUs”. Em outras palavras, o TensorFlow é “embaraçosamente paralelo” desde a sua instalação.
Em um teste de ajuste de hiperparâmetros, o grupo de cientistas da Databricks configurou um cluster de 13 nós para realizar o teste. A equipe conseguiu atingir uma taxa de precisão de 99,47%, uma melhora de 34% contra executar o processo com as configurações padrões do TensorFlow. Cada nó executou um modelo diferente, assim, o treinamento em paralelo foi realizado.
Dimensionando com o TensorFlow e o PyTorch
O TensorFlow e o PyTorch têm suporte nativo para machine learning distribuído. O TensorFlow tem uma API chamada tf.distribute.strategy que permite que as cargas de trabalho de treinamento sejam distribuídas entre nós, TPUs e GPUs. Os benefícios de tf.distribute.strategy incluem os seguintes:
- Escala de nó único para vários nós e GPUs/TPUs.
- Suporta vários grupos de usuários.
- Melhora o desempenho.
- Pode ser utilizado com Keras.
- Suporta treinamento síncrono e assíncrono:
- Síncrono: “todos os trabalhadores treinam sob diferentes grupos de dados de entrada em sincronia e agregam gradientes em cada etapa”.
- Assíncrono: “todos os trabalhadores estão treinando independentemente sobre os dados de entrada e atualizando variáveis de forma assíncrona”.
- Seis estratégias são suportadas: 1) MirroredStrategy 2) TPUStrategy 3) MultiWorkderMirroredStrategy 4) CentralStorageStrategy 5) ParameterServerStrategy e 6) OneDeviceStrategy.
PyTorch tem um recurso chamado DataParallel que é uma “técnica de treinamento distribuído” que permite que o treinamento seja replicado em diferentes GPUs no mesmo nó para acelerar o treinamento. Outro recurs do PyTorch é o Model Parallel, que “divide um único modelo em diferentes GPUs, em vez de replicar todo o modelo em cada GPU”. Por exemplo: se um modelo contiver 10 camadas (entrada + saída + 8 ocultas), cada camada pode ser colocada em um GPU em dispositivos diferentes. Se uma máquina é usada com 2 GPUs, então 5 camadas podem ser processadas em cada GPU.
Processamento de Stream
Agora podemos discutir outro tipo de processamento chamado processamento de stream. O processamento de stream envolve a ingestão e o processamento de sequências de dados ao vivo. Esses dados podem ser qualquer coisa, desde weblogs a dados de dispositivos IoT, dados de sensores e assim por diante. Dois processadores de stream populares são o Kafka e o Apache Spark Streaming. As duas ferramentas serão utilizadas em nossa arquitetura de referência. O Spark Streaming e o Kafka são relativamente bem conhecidos e usados por milhares de empresas em todo o mundo. O Spark Streaming é uma extensão do Spark e fornece recursos de processo de stream para o Spark, uma vez que ele não suporta isso nativamente.
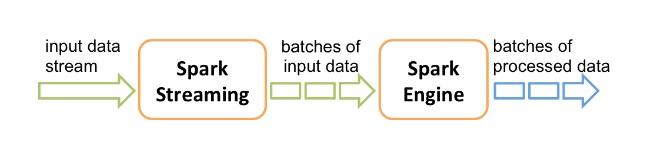
Conforme ilustrado no diagrama abaixo, o Spark Streaming ingere fluxos de dados em tempo real de uma fonte de dados. Em seguida, divide esses fluxos em lotes chamados RDDs. A coleta de lotes RDD é o DStream que representa o “fluxo contínuo de dados”. Depois disso, os RDD alimentam o Spark. A partir daí, os dados podem sofrer uma transformação adicional ou ser alimentados em outro sistema como um banco de dados ou um modelo de ML.
Spark Streaming
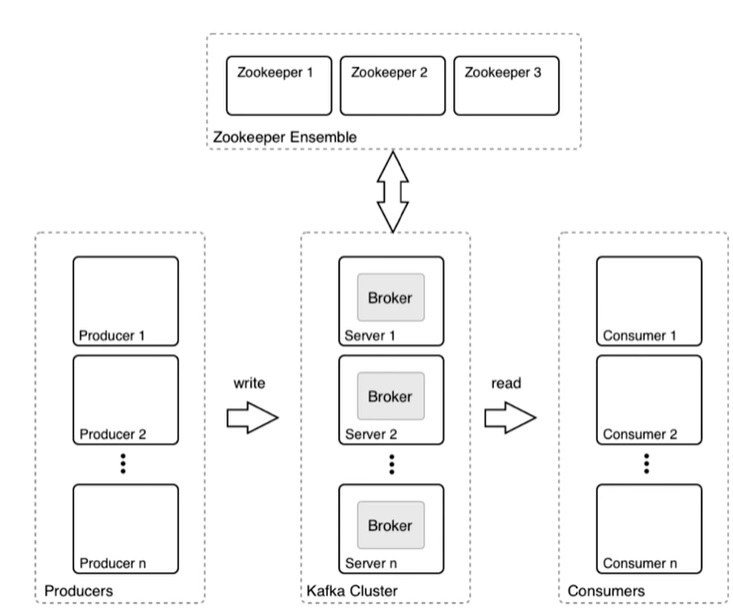
O Kafka é o sistema mais robusto dos dois. No gráfico abaixo, as partes do Kafka são ilustradas. O produtor é qualquer aplicativo ou sistema que gera dados brutos, como um dispositivo IoT, servidor web, banco de dados, roteador, etc. O cluster de Kafka ingere os dados brutos do produtor, faz filas se o volume de dados for alto. Depois encaminha para o consumidor que assina ao Tópico. O Tópico é o nome do feed ou categoria de dados.
Em resumo, existem stacks disponíveis para ajudar na ingestão de dados, processamento paralelo, processamento de stream, computação distribuída e armazenamento.