Hoje, existem mais de 300 motores de bancos de dados no mercado. Contudo, poucos bancos de dados têm sido desenvolvidos especificamente para Machine Learning (ML). Existe um produto chamado MLDB que é um banco de dados de código aberto para ML. No entanto, a empresa por trás do banco de dados foi adquirida pela Element AI. Kinetica é outra startup que desenvolveu um produto para a análise de dados de Machine Learning que espalha a carga de trabalho de computação entre GPUs e CPUs simultaneamente.
O banco de dados Kinetica funciona direto na memória como Apache Spark. Bancos de dados in-memory são consideravelmente mais rápidos do que aqueles que funcionam puramente no disco rígido. Kinetica refere-se ao seu banco de dados como um “banco de dados vetorizado, colunar e memory-first, projetado para cargas de trabalho analíticas (OLAP)” que “distribui automaticamente qualquer carga de trabalho entre CPUs e GPUs para obter resultados otimizados”.
Assim, a Kinetica é capaz de distribuir as cargas de trabalho de Inteligência Artificial entre CPUs e GPUs, reduzindo o custo geral do sistema, uma vez que as placas de GPU são caras. A arquitetura Kinetica é ilustrada abaixo.
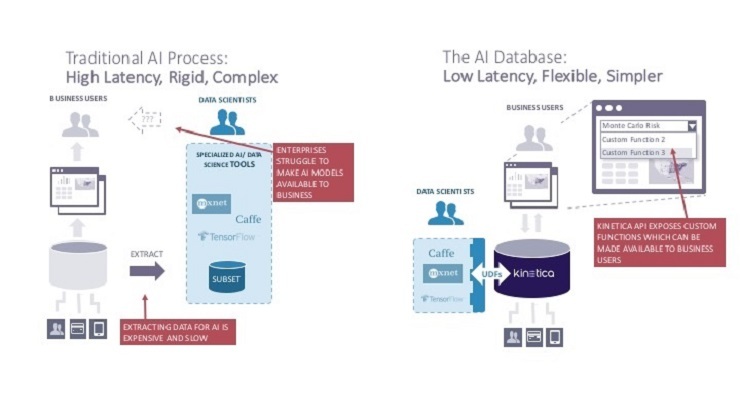
Em um white paper, Kinetica explica um dos benefícios da arquitetura do seu sistema – ele coloca processos computacionalmente pesados nas GPUs e os processos menos intensivos em recursos nas CPUs. Além disso, ele irá alavancar a RAM na placa-mãe e a memória nas placas GPU para otimizar o desempenho.
Usando uma abordagem baseada em colunas, Kinetica é capaz de usar o armazenamento de forma mais eficiente, em um ambiente de análise de dados e também de fornecer resultados às consultas rapidamente. Pelo lado negativo, um banco de dados de GPU não é o melhor para modelos de treinamento de ML. Para esse caso, o Apache Spark é o produto ideal.
Duas características importantes
• A carga de processamento é espalhada entre GPUs e CPUs
• A memória GPU e a RAM do sistema são usadas para processar e armazenar dados para tarefas de IA
O Modelo de Consumo
O Diretor de Pesquisa da IDC, Sriram Subramanian, publicou um artigo sobre IA Stacks (pilhas de Inteligência Artificial) modernas que descreve os diferentes modelos de consumo. Embora a imagem não explique o funcionamento de um banco de dados para Machine Learning, ilustra as diferentes camadas das pilhas de IA, incluindo as de computação e a de dados.
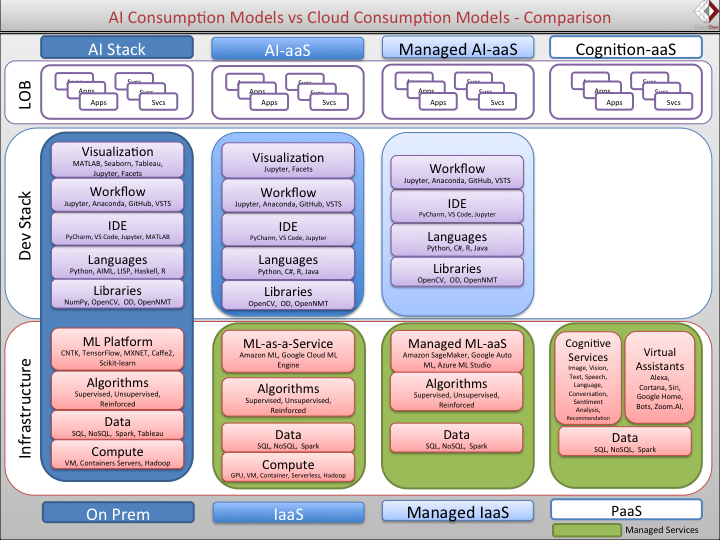
Sriram divide os modelos de consumo em quatro tipos diferentes. Na coluna on-premise, a camada de computação está na parte inferior da pilha e a camada de dados está logo acima dela. No entanto, para o treinamento de ML, a computação ocorre na GPU e nas CPUs. O tipo de servidor seria o tipo de sistema que está sendo usado para ML, como um servidor dedicado, um contêiner, uma VM ou um servidor compartilhado, talvez?
Perguntas importantes
• É um banco de dados mesmo necessário para o treinamento de ML?
• Pode um sistema de arquivos como o Hadoop substituir um banco de dados rigorosamente para treinamento de modelos e a inferência (após o término do treinamento)?
Apache Kafka
O Apache Kafka é um mecanismo de processamento de streams popular, projetado para funcionar como um sistema altamente escalável que pode processar um alto volume de feeds de dados em tempo real. As partes do Kafka incluem os 1) produtores, 2) o cluster e 3) os consumidores. As três partes permitem que as empresas insiram dados, os processem e produzam um resultado de maneira organizada. O LinkedIn originalmente desenvolveu o Kafka e depois doou-o para a Fundação Apache. Os desenvolvedores do Kafka deixaram o LinkedIn e criaram uma empresa chamada Confluent, que se concentra no Kafka.
Kai Waehner, evangelista de Confluent, criou uma arquitetura de referência e um ciclo de vida de desenvolvimento de ML que é ilustrado a seguir. No lado esquerdo estão os sistemas que fornecem dados para Kafka e Hadoop. Kafka ingere dados em tempo real e Hadoop os dados em lote. TensorFlow e H20.ai localizam-se ao lado do Hadoop. O Hadoop não é um banco de dados, mas um sistema de arquivos distribuídos que funciona eficientemente em grandes clusters de servidores de commodities. No entanto, o artigo e a arquitetura não fornecem profundidade suficiente para formar qualquer tipo de opinião ou conclusão.
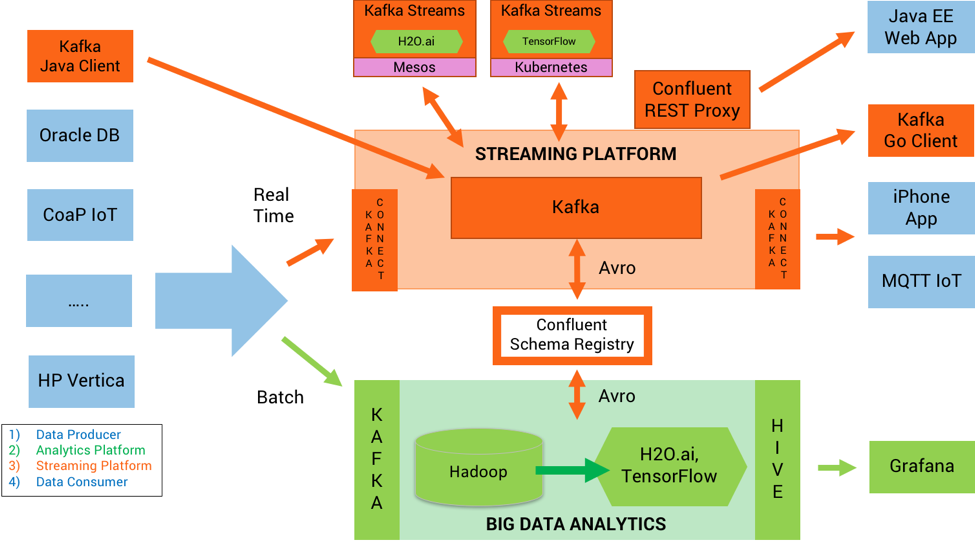
Em resumo, existe uma necessidade de mais bancos de dados desenvolvidos para Machine Learning.