Você provavelmente já percebeu que uma pesquisa típica no Google, Bing ou Yahoo leva menos de um segundo para exibir um resultado na sua tela. No entanto, para isso acontecer, o motor de busca do seu navegador precisa estar atualizado tanto com o conteúdo novo quanto com o antigo, de modo que toda essa informação esteja disponível quando necessário. Os engenheiros desenvolvem motores de busca com base em componentes, como web crawlers, bots de indexação, de ranking e de resolução de solicitações, para fornecer respostas rápidas.
Os motores de busca utilizam esses componentes (algoritmos) para localizar, classificar e disponibilizar os “melhores” sites, documentos, imagens e outros tipos de conteúdo, tornando a navegação dos usuários mais fácil na vasta quantidade de recursos disponíveis na Internet. Além disso, esses motores devem ser capazes de fornecer resultados categorizados com conteúdo relevante.
Entretanto, esses motores não são criados exclusivamente para os principais navegadores web. As empresas de todo o mundo e até mesmo os profissionais de diferentes setores podem desenvolver seus próprios motores para diversas aplicações, como por exemplo, a recuperação de dados de artigos, ofertas de emprego ou preços de produtos de moda em milhares de sites.
Nas próximas seções apresentaremos mais informações sobre os componentes de um motor de busca, além de uma ferramenta de open-source para realizar web scraping.
Mas, o que é web crawling e web scraping?
Embora essas duas definições utilizem algoritmos semelhantes, o web crawling e o web scraping são técnicas diferentes empregadas para coletar dados da Internet.
Web crawling
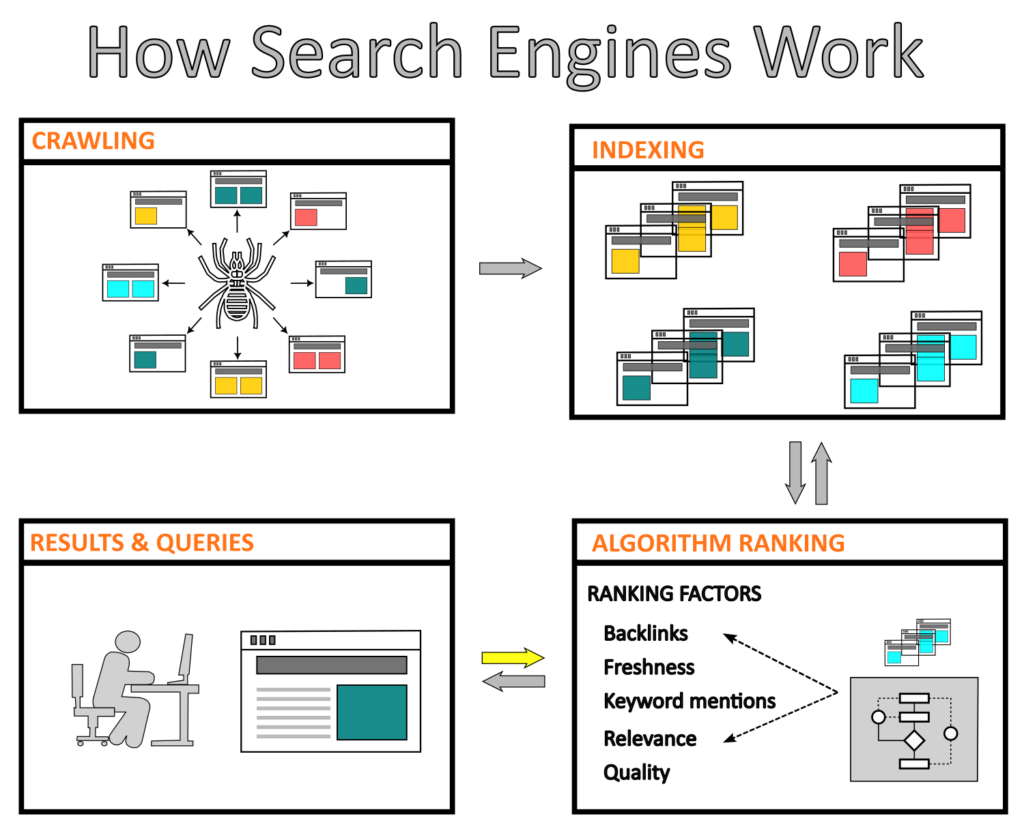
O web crawler, também conhecido como bot ou spider, rastreia toda a Internet de forma metódica e automática. Possui um algoritmo que analisa vários sites para coletar informações e criar entradas que serão utilizadas posteriormente para indexar esses sites.
O processo de crawling começa com uma lista de URLs a serem visitados para logo baixar, analisar o conteúdo e extrair informações, tais como links, arquivos HTML, CSS ou de JavaScript na forma de itens. Por fim, o rastreador processa esses elementos usando tarefas de limpeza, validação e persistência.
Em virtude de que milhares de sites são criados diariamente, o web crawler deve passar por esse processo repetidas vezes, adicionando sites novos e atualizados à sua lista de URLs.
De maneira geral, o web crawling é um processo essencial de um motor de busca no qual algoritmos pesquisam e baixam conteúdos específicos da Internet de forma sistemática. Esse conteúdo é utilizado somente para indexar e classificar os sites.
Web scraping
Por outro lado, o web scraping é o processo de download de dados de sites especificados pelo desenvolvedor. Em outras palavras, os Devs podem trabalhar em um site, identificando e extraindo dados de interesse. Essa técnica pode ser usada para uma ampla gama de aplicações, tais como:
Pesquisa: buscar e baixar informações é o primeiro passo em um projeto para qualquer pesquisador, seja para fins acadêmicos, de marketing, financeiros ou outros relacionados aos negócios.
Retail/ E-commerce: Atualmente, as empresas empregam regularmente técnicas de marketing para manter sua competitividade. Por exemplo, elas devem estar cientes de preços, ofertas especiais e outros fatores externos para se manterem um passo à frente de seus concorrentes.
Proteção cibernética: A criação de conteúdo está se tornando cada vez mais uma parte essencial dos negócios. Embora grande parte desse conteúdo seja público, como preços de produtos na Amazon ou dados de pesquisa em uma publicação, dados pessoais e propriedade intelectual estão expostos a ataques cibernéticos de atores que buscam lucrar ilegalmente. A coleta de dados permite que os proprietários desses dados monitorem e protejam informações confidenciais.
Em geral, o web scraping simplifica a extração sistemática e automática de dados específicos de um site para que sejam processados e analisados em estudos posteriores pelos usuários.
Indexação de sites
A indexação de sites envolve coletar, categorizar e armazenar informações relacionadas a esses sites para criar um banco de dados de fácil acesso. Uma vez que os sites estão indexados, os motores de busca podem rapidamente recuperar e fornecer resultados de uma consulta.
Martin Splitt, WebMaster e Analista de tendências do Google, fornece uma explicação clara e concisa sobre a web indexing:
“Uma vez que temos as informações dos sites(…), é necessário realizar uma análise. Para fazer isso, devemos descobrir do que se trata o conteúdo e a sua finalidade. Em essência, esse é o segundo estágio num motor de busca, conhecido como indexação”.
Ranking dos motores de busca
Quando um motor de busca recebe uma query, é necessário que ele tenha a capacidade de exibir resultados de acordo a vários critérios de avaliação. Isso é realizado através de um algoritmo complexo que compara palavras-chave e frases entre a query e o conteúdo indexado, para depois categorizar os resultados com base nos fatores de ranking.
Por exemplo, o Googlebot possui vários fatores de ranking definidos pela relevância, qualidade e facilidade de uso do conteúdo, assim como também pela localização e outros parâmetros.
Melhorando o ranking de sites com estratégias de SEO
Quando os motores de busca não conseguem rastrear um novo site, ele fica impossibilitado de ser indexado e exibido nos resultados de busca. Isso pode ser causado por vários fatores, como erros no arquivo “robots.txt”, problemas de conectividade com o servidor, problemas de design do site ou problemas relacionados ao conteúdo. Embora novos sites precisem de tempo (em torno de dias) para serem rastreados e indexados pelos motores de busca, a otimização e a solução dos problemas técnicos podem melhorar a visibilidade e o ranking do site.
Por isso, os profissionais previamente treinados utilizam técnicas de SEO (Search Engine Optimization) para aprimorar o conteúdo de acordo com determinadas estratégias de otimização, facilitando sua indexação e posicionamento nos resultados de busca.
Para melhorar a classificação do conteúdo, considere as seguintes indicações:
- Utilize URLs curtas.
- Adicione conteúdo novo.
- Crie um título com um número reduzido de caracteres.
- Insira uma imagem relacionada ao tema.
- Crie parágrafos com no máximo 300 palavras.
- Se você estiver escrevendo um post, mencione pelo menos 1-3 pessoas.
- Defina uma palavra-chave, use-a no título e mantenha sua densidade ao longo do texto.
Biblioteca de Python para web scraping
O web scraping está se tornando cada vez mais popular na extração de dados de sites. Para realizar o web scraping, é necessário ter pelo menos conhecimento básico em HTML e CSS, pois isso permitirá que você entenda a estrutura de um site. Além disso, é preciso saber como usar ferramentas como BeautifulSoup ou Scrapy para criar um algoritmo que possibilite a extração automática de dados.
É importante ressaltar que a extração de dados deve ser legal e ética, caso contrário, pode gerar futuras sanções. Para obter mais informações verifique a Lei de Direitos Autorais do Milênio Digital (DMCA por suas siglas em inglês).
O Scrapy é uma biblioteca ou pacote de código aberto escrito em Python, que permite aos usuários extrair dados de sites. Embora tenha sido inicialmente criado para fins de web scraping, também é usado como um web crawler de uso geral. O Scrapy é baseado em “spiders” (um componente do crawler), que são um tipo de função, também chamada de classe, que define a técnica de extração de dados. Atualmente, a Zyte, uma empresa especializada em web crawling, oferece suporte a essa ferramenta.
“É muito bom trabalhar com o Scrapy. Ele remove a maior parte da complexidade das tarefas de web scraping, permitindo que usuários se concentrem nas tarefas principais de extração de dados.” –Jacob Perkins, autor do livro “Python 3 Text Processing with NLTK 3 Cookbook”.
Para começar a usar o Scrapy, você precisa instalar um Python IDE em sua máquina e executar no command prompt ou terminal o comando “pip install scrapy”. Se você é usuário de alguma distribuição de Anaconda, utilize “conda install -c conda-forge scrapy”.