O Kubeflow é uma plataforma desenvolvida pelo Google para ajudar os desenvolvedores na implementação e gestão de workflows de ML (Machine Learning) no Kubernetes (K8s).
Em um contexto mais abrangente, o Machine Learning não se baseia somente na construção, treinamento e implementação de códigos. Essas três tarefas são apenas uma parte de um conjunto de etapas do workflow que inclui a coleta e validação de dados, o monitoramento, a busca de ferramentas de análise, a escolha de uma infraestrutura de serviço, a extração de tendências e o uso de programas para a gestão de processos e recursos de computação.
Por esse motivo, as tarefas de workflows de ML estão se tornando mais complexas e exigindo tempos de processamento mais longos, muitas vezes envolvendo diferentes equipes e com inúmeras tarefas. Ferramentas como o Kubeflow buscam simplificar e agilizar esses workflows, fornecendo uma plataforma integrada e dedicada para o gerenciamento de todo o processo.
Neste post, revisaremos algumas das principais tarefas realizadas durante a modelagem de ML e mostraremos como a abordagem do Kubeflow torna tudo isso mais simples.
Cenário inicial: o Kubernetes e as MLOPs
A técnica de machine learning
O machine learning é um subconjunto do campo da inteligência artificial voltado para o estudo e construção de modelos de aprendizado constituídos por algoritmos avançados. Esses algoritmos são comumente baseados em modelos estatísticos, inferências, assim como também estratégias tais como redes neurais artificiais, árvores de decisão, análise de regressão, redes bayesianas, algoritmos genéticos, entre outros. Apesar dos avanços significativos obtidos nos últimos anos, o ML ainda apresenta alguns desafios.
Por exemplo, nas etapas iniciais da modelagem de ML, cientistas e engenheiros de dados podem precisar executar grandes experimentos de forma precisa e reproduzível. Além disso, eles podem precisar da liberdade para executar workflows de ML específicos nas suas próprias instalações e outros workflows em serviços de nuvem para aumentar os recursos e facilitar a implementação, bem como ter a capacidade de executar tarefas em paralelo. Portanto, esses profissionais, apesar de seu amplo conhecimento, precisam estar à frente no uso de novas tecnologias e ferramentas voltadas para esse fim.
Independentemente do número de experimentos, do tipo de modelo e do ambiente em que são executados, o processo padrão de ML pode ser dividido nas seguintes etapas fundamentais:
- Análise do problema: um modelo de ML geralmente começa com a análise do problema antes de criar o código. Isso pode incluir entender o contexto do problema, coletar, preparar, limpar e analisar dados para obter insights e definir a melhor abordagem (modelo de ML) para resolver o problema.
- Criação do código e avaliação de laboratório: essa etapa consiste em selecionar e escrever o algoritmo apropriado, e avaliar o modelo para uma quantidade não tão grande de dados. Essa fase é considerada mais uma etapa de laboratório.
- Ajuste de parâmetros do modelo: os engenheiros devem avaliar a performance do modelo de ML usando métricas como erro relativo, nível de eficiência, exatidão ou precisão. Além disso, eles poderiam introduzir um processo de otimização iterativo para otimizar coeficientes ou fatores de ponderação do modelo.
- Implementação e gestão: uma vez que o modelo foi aprovado de acordo com os níveis de precisão requisitados, a última etapa para um cientista de dados é a implementação do modelo em um ambiente de produção. Isso pode significar lidar com grandes quantidades de dados, monitorar a performance do modelo de ML, fazer os ajustes necessários nos coeficientes do modelo, aperfeiçoamento e muito mais.
Essa certamente não é a regra de ouro, mas serve ao propósito do nosso post. É necessário entender que o processo de ML segue essas etapas básicas e muitas outras, portanto, devemos imaginar que abordagens específicas variem em função dos casos. No entanto, à medida que qualquer código de ML evolui, exige também mais recursos computacionais, ambientes maiores como uma nuvem e ferramentas especializadas para gerenciá-los de forma eficiente. Portanto, é aqui onde o Kubernetes tem um papel importante.
O Kubernetes
O Kubernetes é um software de orquestração de containers de código aberto que automatiza a gestão de aplicações em containers. Ele é multi-plataforma e abstrai a infraestrutura subjacente, fornecendo um conjunto consistente de APIs. Os usuários podem definir o estado desejado de suas aplicações de forma declarativa usando arquivos de configuração chamados manifestos (manifests). Esses manifestos especificam todos os aspectos do ciclo de vida de uma aplicação, como requisitos de armazenamento, configurações de rede, estratégias de balanceamento de carga, verificações de integridade e políticas de atualização.
O Kubernetes oferece vários benefícios para implementações de ML, incluindo:
- Escalabilidade: O Kubernetes dimensiona automaticamente a carga de trabalho para atender à demanda, caso você esteja lidando com conjuntos de dados maiores ou utilizando várias máquinas para treinamento distribuído.
- Isolamento: Os containers fornecem um alto nível de isolamento que traz benefícios durante a execução de tarefas que incluem dados confidenciais.
- Monitoramento e observabilidade: Os usuários podem empregar recursos de monitoramento para inspecionar o status e a performance dos workflows de ML.
- Portabilidade: O K8s facilita aos usuários a implementação de modelos de ML nas instalações, na nuvem ou em um ambiente híbrido, o que o torna uma opção flexível para diferentes cenários.
No entanto, isso não significa que esteja tudo bem e que não haja problemas e desafios a superar. O Kubernetes não possui a capacidade de executar todas as etapas exigidas pelos workflows de ML. Além disso, sua implementação na plataforma de Kubernetes pode ser problemática devido à necessidade de combinar diferentes ferramentas e bibliotecas com dependências e requisitos específicos. Por esse motivo, o Google criou o projeto Kubeflow e seu conjunto completo de ferramentas.
Como implementar e gerenciar com o Kubeflow
O Kubeflow é uma plataforma de código aberto que simplifica e automatiza workflows de ML no Kubernetes. Ele permite que os engenheiros gerenciem e personalizem vários modelos de ML, além de definirem pipelines como processos de vários estágios, incluindo a preparação de dados, o treinamento e o ajuste.
O Kubeflow é altamente reconhecido como uma ferramenta simples de usar, fornecendo componentes e ferramentas intuitivas, como Kubeflow Notebooks, Training Operators, Kubeflow Pipelines, Model Serving, Katib, entre outros.
Componentes
Kubeflow Notebooks
O Kubeflow permite a integração com o JupyterHub, uma ferramenta que facilita o uso de IDEs baseados na web em um cluster de Kubernetes e sendo executado como Pods. Além disso, o Kubeflow oferece suporte nativo para Visual Studio Code, JupyterLab e RStudio, permitindo aos usuários criar containers de Notebooks em um cluster.
Kubeflow Pipelines
O Pipelines é uma ferramenta para criar workflows de ML de extremo a extremo, e oferece uma interface fácil de usar para o gerenciamento de pipelines. O Kubeflow Pipelines permite aos usuários coordenar diferentes etapas de um pipeline de ML, como processamento, treinamento e serviço. O Pipelines também oferece suporte ao uso de containers de Docker para facilitar o empacotamento e a implementação de forma portátil e consistente.
Katib
O Katib é uma ferramenta baseada em Kubernetes para processos de aprendizado (AutoML) que inclui recursos como ajuste de hiperparâmetros, parada antecipada e pesquisa de arquitetura neural (NAS, por sua sigla em inglês). Ele suporta várias estruturas e oferece uma ampla variedade de algoritmos de AutoML, incluindo otimização bayesiana, estimadores Tree of Parzen, pesquisa aleatória, pesquisa de arquitetura diferenciável e muito mais. Atualmente, o Katib está na versão beta.
Training Operators
Os Kubeflow Training Operators são um conjunto de recursos personalizados do Kubernetes, como TFJob, PaddleJob, PyTorchJob e outros, que fornecem uma forma simples de automatizar a implementação e o dimensionamento de workflows de treinamento de ML.
Model Serving
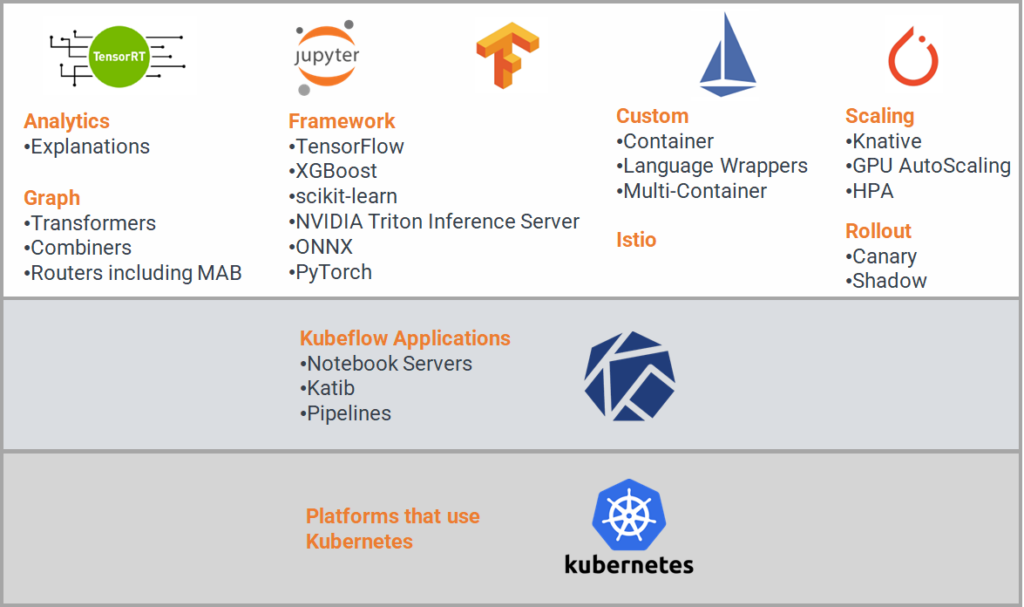
O Kubeflow oferece dois sistemas de serviço de modelo: o KFServing e o Seldon Core, cada um equipado com um conjunto abrangente de recursos para atender às diversas necessidades dos engenheiros. Esses recursos incluem suporte para diferentes frameworks de ML, gráficos, análises, scaling, serviço personalizado e integração com o Istio para a gestão de tráfego universal, uso de serviços de telemetria e como método de segurança em implementações complexas.
Resumindo
O Kubeflow é um mecanismo de workflows nativo do Kubernetes de código aberto projetado para a implementação de workflows complexos de ML. Essa ferramenta é apenas uma entre as muitas no ecossistema de código aberto focadas em modelos de ML (mais informação em nosso post sobre o Argo Workflows).
O Kubeflow nasceu dentro do Google, originalmente projetado para executar tarefas do TensorFlow, mas cresceu e agora oferece suporte a estruturas e arquiteturas multi-nuvem. Grandes empresas de tecnologia como IBM, Red Hat, Cisco e outras, estão contribuindo para este projeto. Além disso, o Kubeflow oferece suporte a uma ampla variedade de projetos, como TensorFlow, PyTorch, Chainer, MXNet, Ambassador, XGBoost, Istio, Nuclio e muito mais.